
- Visual Computing
Weakly-Supervised Visual Grounding of Phrases with Linguistic Structures
- Press Release: Computers using linguistic clues to deduce photo content
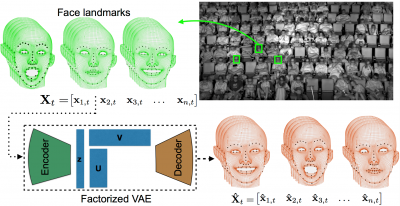
- Visual Computing
Factorized Variational Autoencoders for Modeling Audience Reactions to Movies
- Press Release: Neural nets model audience reactions to movies

- Robotics
Joint Optimization of Robot Design and Motion Parameters using the Implicit Function Theorem

- Visual Computing
IRIDiuM+: Deep Media Storytelling with Non-Linear Light Field Video

- Machine Learning & Data Analytics
Kernel-Predicting Convolutional Networks for Denoising Monte Carlo Renderings

- Robotics
Active Vertical Stabilization Mechanism for Lightweight Handheld Cameras
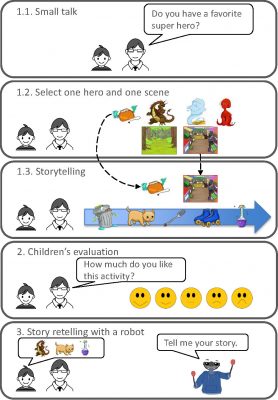
- Machine Learning & Data Analytics
Collaborative Storytelling between Robot and Child: A Feasibility Study
- Press Release: When kids talk to robots: Enhancing engagement and learning
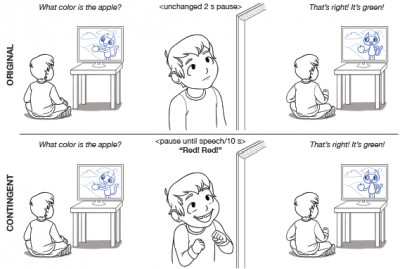
- Machine Learning & Data Analytics
Investigating the Effects of Interactive Features for Preschool Television Programming
- Press Release: When kids talk to robots: Enhancing engagement and learning
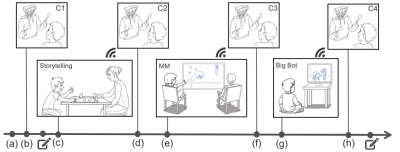
- Machine Learning & Data Analytics
Persistent Memory in Repeated Child-Robot Conversations
- Press Release: When kids talk to robots: Enhancing engagement and learning
- Visual Computing
Practical Path Guiding for Efficient Light-Transport Simulation

- Visual Computing
Groups Re-identification with Temporal Context

- Human Computer Interaction
Cross-modal Correspondence between Vibrations and Colors
Page 12 of 59