Abstract
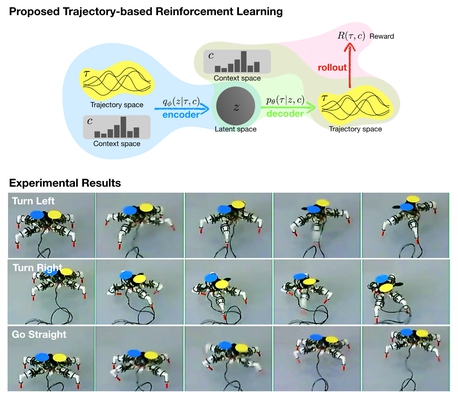
In this paper, we propose a trajectory-based reinforcement learning method named deep latent policy gradient (DLPG) for learning locomotion skills. We define the policy function as a probability distribution over trajectories and train the policy using a deep latent variable model to achieve sample efficient skill learning. We first evaluate the sample efficiency of DLPG compared to the state-of-the-art reinforcement learning methods in simulated environments. Then, we apply the proposed method to a four-legged walking robot named Snapbot to learn three basic locomotion skills of turn left, go straight, and turn right. We demonstrate that, by properly designing two reward functions for curriculum learning, Snapbot successfully learns the desired locomotion skills with moderate sample complexity.
Additional Content
Copyright Notice
The documents contained in these directories are included by the contributing authors as a means to ensure timely dissemination of scholarly and technical work on a non-commercial basis. Copyright and all rights therein are maintained by the authors or by other copyright holders, notwithstanding that they have offered their works here electronically. It is understood that all persons copying this information will adhere to the terms and constraints invoked by each author’s copyright. These works may not be reposted without the explicit permission of the copyright holder.