Abstract
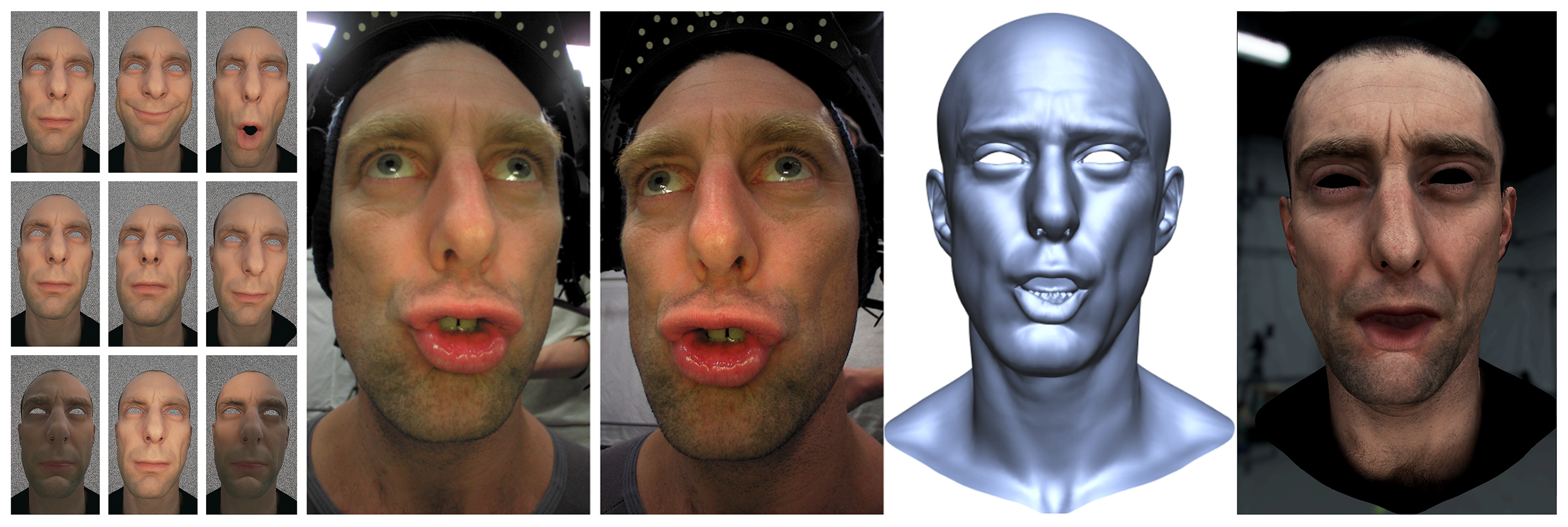
We present a real-time multi-view facial capture system facilitated by synthetic training imagery. Our method is able to achieve high-quality markerless facial performance capture in real-time from multi-view helmet camera data, employing an actor-specific regressor. The regressor training is tailored to specified actor appearance and we further condition it for the expected illumination conditions and the physical capture rig by generating the training data synthetically. In order to leverage the information present in live imagery, which is typically provided by multiple cameras, we propose a novel multi-view regression algorithm that uses multi-dimensional random ferns. We show that higher quality can be achieved by regressing on multiple video streams than previous approaches that were designed to operate on only a single view. Furthermore, we evaluate possible camera placements and propose a novel camera configuration that allows to mount cameras outside the field of view of the actor, which is very beneficial as the cameras are then less of a distraction for the actor and allow for an unobstructed line of sight to the director and other actors. Our new real-time facial capture approach has immediate application in on-set virtual production, in particular with the ever-growing demand for motion-captured facial animation in visual effects and video games.
Additional Content
Copyright Notice
The documents contained in these directories are included by the contributing authors as a means to ensure timely dissemination of scholarly and technical work on a non-commercial basis. Copyright and all rights therein are maintained by the authors or by other copyright holders, notwithstanding that they have offered their works here electronically. It is understood that all persons copying this information will adhere to the terms and constraints invoked by each author’s copyright. These works may not be reposted without the explicit permission of the copyright holder.