Abstract
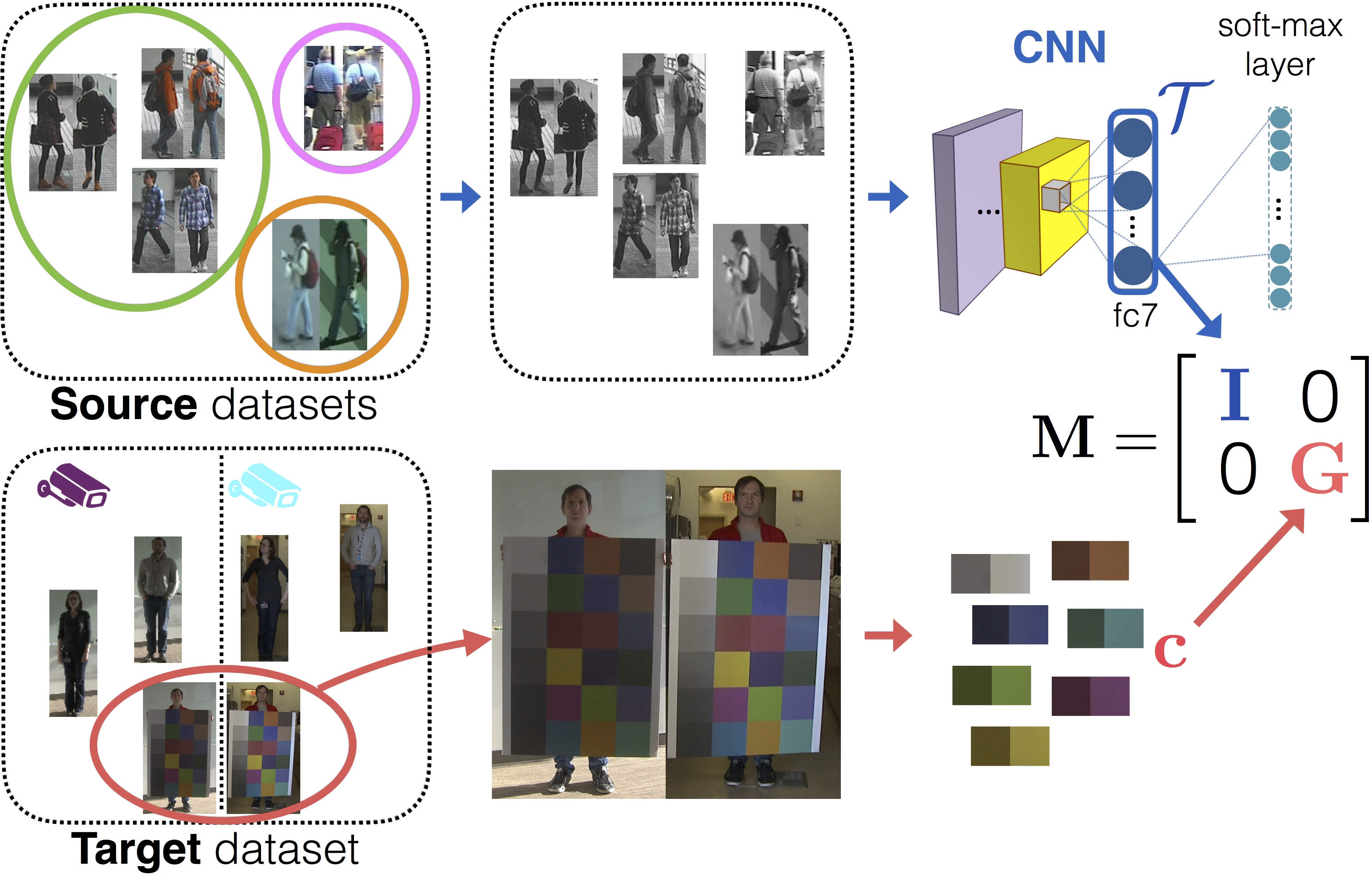
Re-identification of people in surveillance footage must cope with drastic variations in color, background, viewing angle and a person’s pose. Supervised techniques are often the most effective, but require extensive annotation which is infeasible for large camera networks. Unlike previous supervised learning approaches that require hundreds of annotated subjects, we learn a metric using a novel one-shot learning approach. We first learn a deep texture representation from intensity images with Convolutional Neural Networks (CNNs). When training a CNN using only intensity images, the learned embedding is color-invariant and shows high performance even on unseen datasets without fine-tuning. To account for differences in camera color distributions, we learn a color metric using a single pair of ColorChecker images. The proposed one-shot learning achieves performance that is competitive with supervised methods but uses only a single example rather than the hundreds required for the fully supervised case. Compared with semi-supervised and unsupervised state-of-the-art methods, our approach yields significantly higher accuracy.
Copyright Notice
The documents contained in these directories are included by the contributing authors as a means to ensure timely dissemination of scholarly and technical work on a non-commercial basis. Copyright and all rights therein are maintained by the authors or by other copyright holders, notwithstanding that they have offered their works here electronically. It is understood that all persons copying this information will adhere to the terms and constraints invoked by each author’s copyright. These works may not be reposted without the explicit permission of the copyright holder.