Abstract
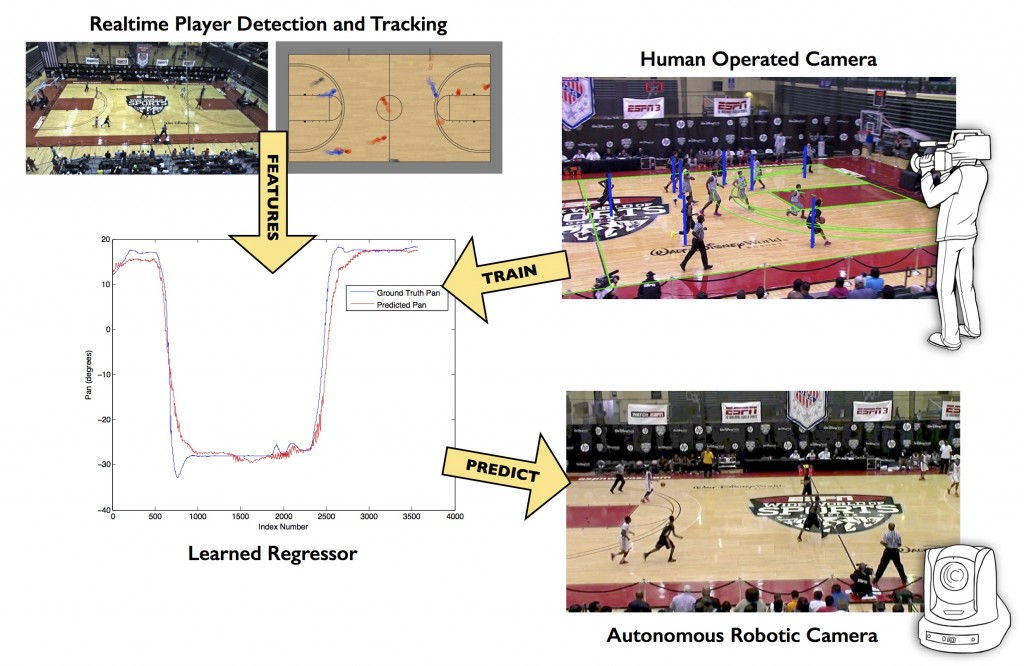
We calibrate broadcast footage of a sports event to learn the pan-tilt-zoom configurations used by a camera operator. We combine this information with tracked player positions to build a structured predictor. Given unseen player positions from a new game, we use the learned predictor to generate target pan-tilt-zoom values for a robotic camera. As a result, the automatically generated broadcast footage looks more human-like.
Copyright Notice
The documents contained in these directories are included by the contributing authors as a means to ensure timely dissemination of scholarly and technical work on a non-commercial basis. Copyright and all rights therein are maintained by the authors or by other copyright holders, notwithstanding that they have offered their works here electronically. It is understood that all persons copying this information will adhere to the terms and constraints invoked by each author’s copyright. These works may not be reposted without the explicit permission of the copyright holder.