Abstract
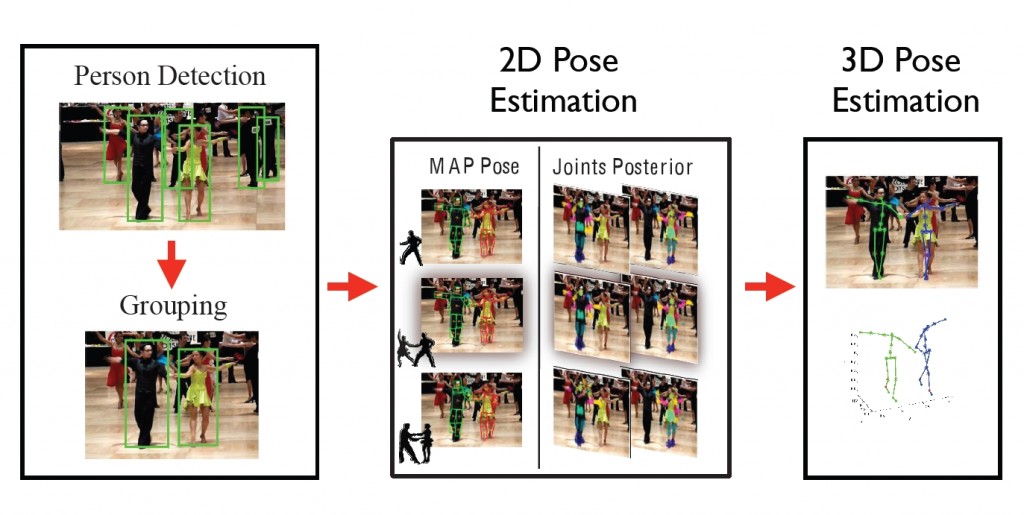
Automatic recovery of 3d pose of multiple interacting subjects from unconstrained monocular image sequence is a challenging and largely unaddressed problem. We observe, however, that by tacking the interactions explicitly into account, treating individual subjects as mutual “context” for one another, performance on this challenging problem can be improved. Building on this observation, in this paper we develop an approach that first jointly estimates 2d poses of people using multi-person extension of the pictorial structures model and then lifts them to 3d. We illustrate e ffectiveness of our method on a new dataset of dancing couples and challenging videos from dance competitions.
Copyright Notice
The documents contained in these directories are included by the contributing authors as a means to ensure timely dissemination of scholarly and technical work on a non-commercial basis. Copyright and all rights therein are maintained by the authors or by other copyright holders, notwithstanding that they have offered their works here electronically. It is understood that all persons copying this information will adhere to the terms and constraints invoked by each author’s copyright. These works may not be reposted without the explicit permission of the copyright holder.