Abstract
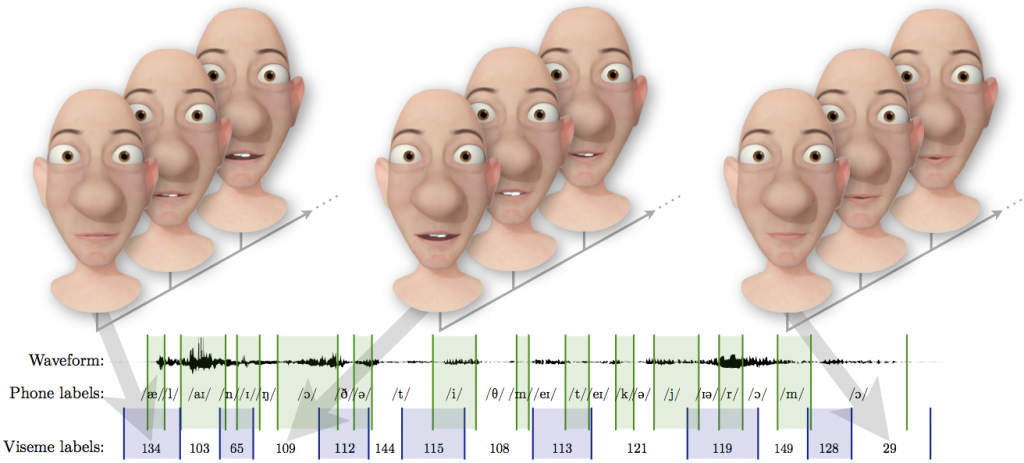
We present a new method for generating a dynamic, concatenative, unit of visual speech that can generate realistic visual speech animation. We redefine visemes as temporal units that describe distinctive speech movements of the visual speech articulators. Traditionally visemes have been surmized as the set of static mouth shapes representing clusters of contrastive phonemes (e.g. /p, b, m/, and /f, v/). In this work, the motion of the visual speech articulators are used to generate discrete, dynamic visual speech gestures. These gestures are clustered, providing a finite set of movements that describe visual speech, the visemes. Dynamic visemes are applied to speech animation by simply concatenating viseme units. We compare to static visemes using subjective evaluation. We find that dynamic visemes are able to produce more accurate and visually pleasing speech animation given phonetically annotated audio, reducing the amount of time that an animator needs to spend manually refining the animation.
Copyright Notice
The documents contained in these directories are included by the contributing authors as a means to ensure timely dissemination of scholarly and technical work on a non-commercial basis. Copyright and all rights therein are maintained by the authors or by other copyright holders, notwithstanding that they have offered their works here electronically. It is understood that all persons copying this information will adhere to the terms and constraints invoked by each author’s copyright. These works may not be reposted without the explicit permission of the copyright holder.