Abstract
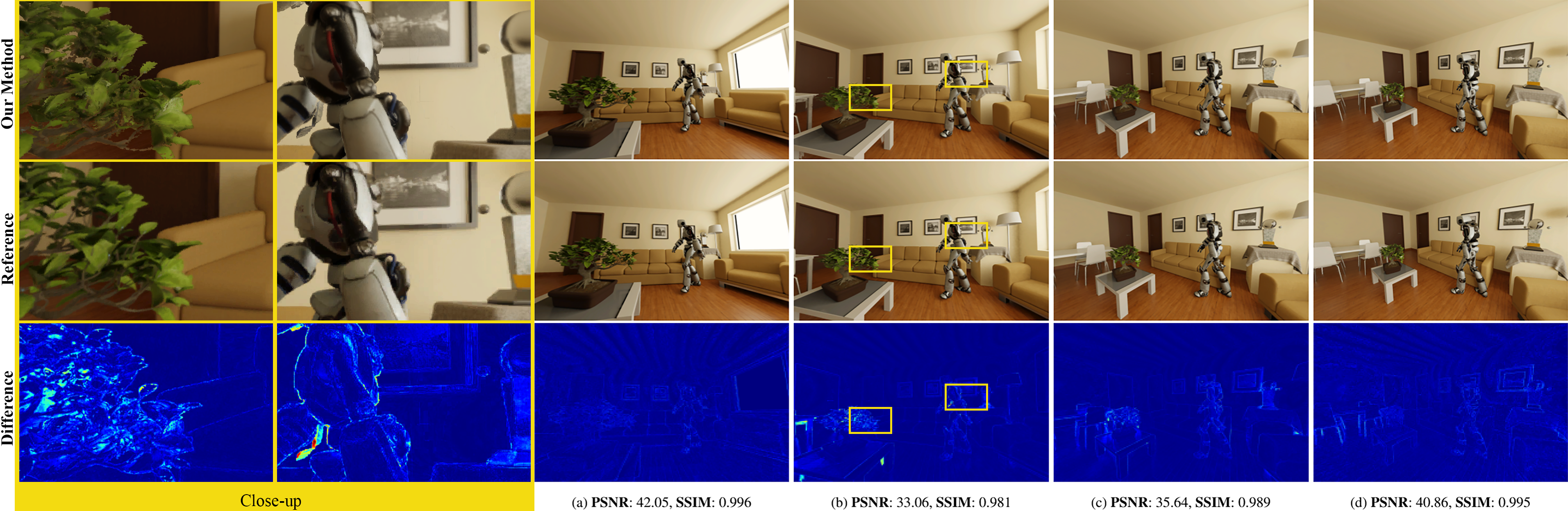
We propose an end-to-end solution for presenting movie quality animated graphics to the user while still allowing the sense of presence afforded by free viewpoint head motion. By transforming offline rendered movie content into a novel immersive representation, we display the content in real-time according to the tracked head pose. For each frame, we generate a set of cubemap images per frame (colors and depths) using a sparse set of cameras placed in the vicinity of the potential viewer locations. The cameras are placed with an optimization process so that the rendered data maximize coverage with minimum redundancy, depending on the lighting environment complexity. We compress the colors and depths separately, introducing an integrated spatial and temporal scheme tailored to high performance on GPUs for Virtual Reality applications. We detail a real-time rendering algorithm using multi-view ray casting and view dependent decompression. Compression rates of 150:1 and greater are demonstrated with quantitative analysis of image reconstruction quality and performance.
Additional Content
Copyright Notice
The documents contained in these directories are included by the contributing authors as a means to ensure timely dissemination of scholarly and technical work on a non-commercial basis. Copyright and all rights therein are maintained by the authors or by other copyright holders, notwithstanding that they have offered their works here electronically. It is understood that all persons copying this information will adhere to the terms and constraints invoked by each author’s copyright. These works may not be reposted without the explicit permission of the copyright holder.