Abstract
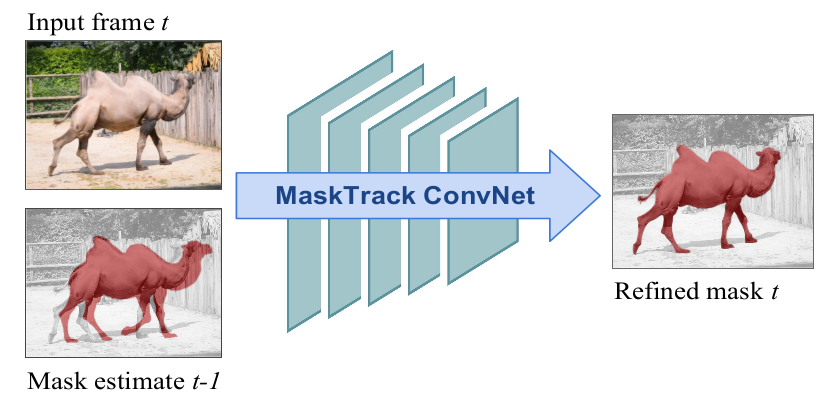
Inspired by recent advances of deep learning in instance segmentation and object tracking, we introduce the concept of convnet-based guidance applied to video object segmentation. Our model proceeds on a per-frame basis, guided by the output of the previous frame towards the object of interest in the next frame. We demonstrate that highly accurate object segmentation in videos can be enabled by using a convolutional neural network (convnet) trained with static images only. The key component of our approach is a combination of offline and online learning strategies, where the former produces a refined mask from the previous’ frame estimate, and the latter allows to capture the appearance of the specific object instance. Our method can handle different types of input annotations such as bounding boxes and segments while leveraging an arbitrary amount of annotated frames. Therefore our system is suitable for diverse applications with different requirements in terms of accuracy and efficiency. In our extensive evaluation, we obtain competitive results on three different datasets, independently from the type of input annotation.
Copyright Notice
The documents contained in these directories are included by the contributing authors as a means to ensure timely dissemination of scholarly and technical work on a non-commercial basis. Copyright and all rights therein are maintained by the authors or by other copyright holders, notwithstanding that they have offered their works here electronically. It is understood that all persons copying this information will adhere to the terms and constraints invoked by each author’s copyright. These works may not be reposted without the explicit permission of the copyright holder.