Abstract
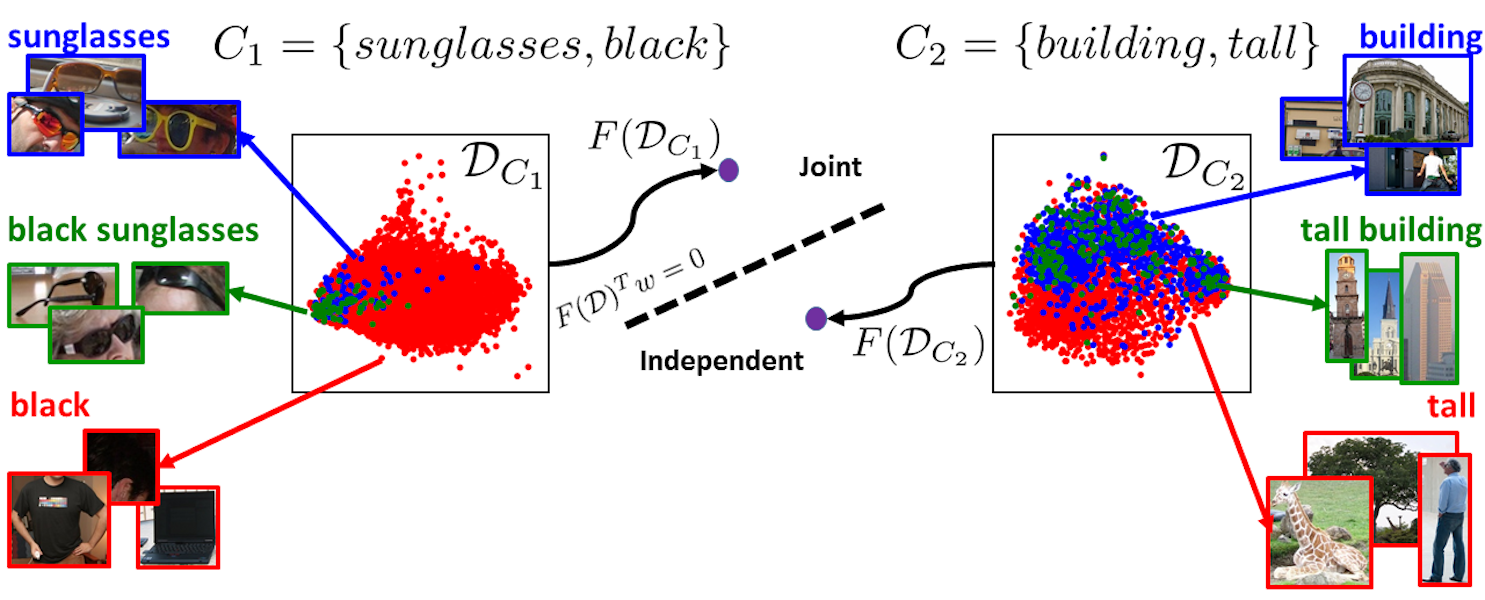
Most approaches for scene parsing, recognition or retrieval use detectors that are either (i) independently trained or (ii) jointly trained for conjunctions of object-object or object-attribute phrases. We posit that neither of these two extremes is uniformly optimal, in terms of performance, across all categories and conjunctions. The choice of whether one should train an independent or composite detector should be made for each possible conjunction separately, and depends on the statistics of the dataset as well. For example, person holding phone may be more accurately modeled using a single composite detector, while tall person may be more accurately modeled as combination of two detectors. We extensively study this issue in the context of multiple problems and datasets. Further, for efficiency, we propose a predictor that is based on a number of category specifi c features ( e.g., sample size, entropy, etc.) for whether independent or joint composite detector may be more accurate for a given conjunction. We show that our prediction and selection mechanism generalizes and leads to improved performance on a number of large-scale datasets and vision tasks.
Copyright Notice
The documents contained in these directories are included by the contributing authors as a means to ensure timely dissemination of scholarly and technical work on a non-commercial basis. Copyright and all rights therein are maintained by the authors or by other copyright holders, notwithstanding that they have offered their works here electronically. It is understood that all persons copying this information will adhere to the terms and constraints invoked by each author’s copyright. These works may not be reposted without the explicit permission of the copyright holder.