Abstract
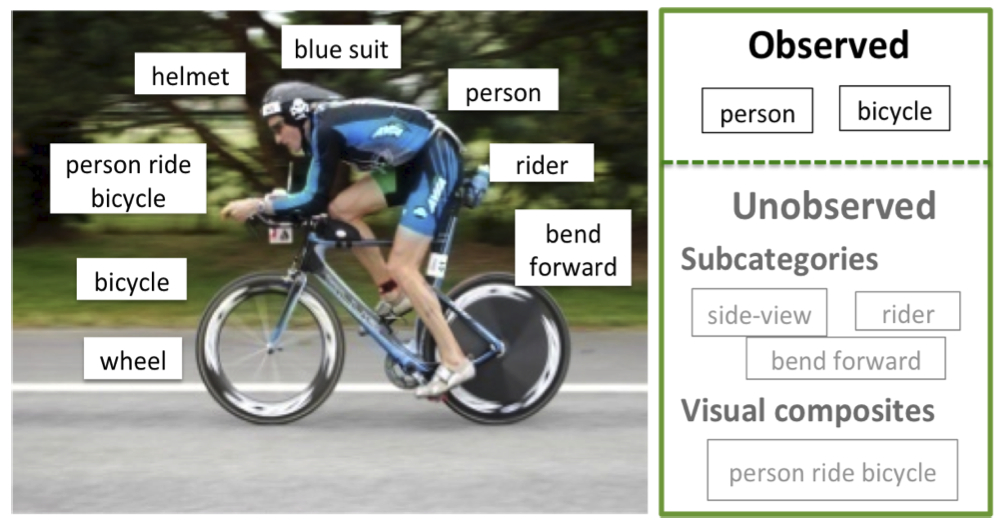
The appearance of an object changes profoundly with pose, camera view, and interactions of the object with other objects in the scene. This makes it challenging to learn detectors based on an object-level label (e.g., ., “car”). We postulate that having a richer set of labelings (at different levels of granularity) for an object, including finer-grained subcategories, consistent in appearance and view, and higher order composites – contextual groupings of objects consistent in their spatial layout and appearance, can significantly alleviate these problems. However, obtaining such a rich set of annotations, including annotation of an exponentially growing set of object groupings, is simply not feasible. We propose a weakly-supervised framework for object detection where we discover subcategories and the composites automatically with only traditional object-level category labels as input. To this end, we first propose an exemplar-SVM-based clustering approach, with latent SVM refinement, that discovers a variable length set of discriminative subcategories for each object class. We then develop a structured model for object detection that captures interactions among object subcategories and automatically discovers semantically meaningful and discriminatively relevant visual composites. We show that this model produces a state-of-the-art performance on UIUC phrase object detection benchmark.
Copyright Notice
The documents contained in these directories are included by the contributing authors as a means to ensure timely dissemination of scholarly and technical work on a non-commercial basis. Copyright and all rights therein are maintained by the authors or by other copyright holders, notwithstanding that they have offered their works here electronically. It is understood that all persons copying this information will adhere to the terms and constraints invoked by each author’s copyright. These works may not be reposted without the explicit permission of the copyright holder.